The loop is not a faster tool; it is a new unit of work.
Draft v0.1 — first posted 22 June 2026 · last revised 23 June 2026 · open for community review. Part of the DIE Framework1.
2.5.1 What makes something a primitive?
In the late 1970s a Harvard MBA student named Dan Bricklin sat watching a professor work through a financial model on a chalkboard. Each time one figure changed, the professor had to rub out a column and recompute by hand every number that depended on it. Bricklin imagined a blackboard that recalculated itself — a grid where you altered one cell and every dependent cell updated on its own. A year later, with Bob Frankston, he shipped VisiCalc.2
The thing he invented was not a program. The program was only the first place it lived. What he invented was the spreadsheet: a grid of cells, dependencies between them, and automatic recomputation. That structure outlived VisiCalc, outlived Lotus 1-2-3, and runs today inside Excel, Google Sheets, and ten thousand workflows that have never heard of any of them. Bricklin built a tool. What escaped from the tool was a primitive.
The distinction is the whole of this section, because we confuse the two constantly. A tool is an instrument you reach for to carry out a task. A primitive is a unit of work that other work is built out of. The hammer is a tool; the assembly line is a primitive. The calculator is a tool; the spreadsheet is a primitive. You can lose a tool and replace it with another tool. You cannot lose a primitive without the things composed from it losing their shape.
Four properties separate a primitive from a mere tool.
It composes. Larger units of work are assembled out of it. A project is a weave of meetings, threads, and spreadsheets — not a thing in its own right, but an arrangement of primitives.
It is substrate-independent. You recognise it across every implementation. A meeting is a meeting in a room, on a call, or in a corridor; the substrate changes and the primitive does not. This is why a primitive survives the death of any particular tool that hosts it.
It has a small, fixed internal structure with a non-arbitrary boundary. A meeting has participants, a span, and a purpose, and you cannot slide where it begins and ends without it ceasing to be a meeting. The boundary is not a matter of taste. Hold on to this one — it is the property that will give us the most trouble later, and the one the rest of this chapter leans on hardest.
And finally, it disappears. Once a primitive exists, people stop seeing it and start organising around it. The meeting, the memo, the email thread, the spreadsheet — nobody designed these as primitives. They earned the status by being composed, recognised, bounded, and then forgotten into infrastructure.
These are the primitives of knowledge work as we inherited it. The wager of this chapter is that there is a new one — the agentic loop — and that it is at the very start of the same path: composing, recognisable, bounded, not yet invisible. The sections that follow test the loop against exactly these four properties. Section 2.5.2 begins where a primitive is most itself: its internal structure, the small fixed set of parts every loop turns out to have.
Open question for the mesh: of the four properties, the boundary is the one we can state cleanly for a meeting and cannot yet state cleanly for a loop. Where does one turn of the loop end and the next begin — and can that line be drawn so firmly that no operator can inflate the agent count n simply by redrawing it? Park the question here. §2.5.2 will have to answer it.
2.5.2 The three components of an agentic loop
The most familiar loop in the world is the one in your car. You set the cruise control to 110, and the car holds it. Going uphill it feeds in throttle; cresting the hill it eases off. You have stopped steering the speed. The loop holds it for you, and it does so with only three moving parts: a target (110), a sensor that reads the actual speed, and a rule that corrects the gap and then checks again. Set those three going and the loop runs without you in it.
That loop is trivial because its target is a single number and its sensor is a speedometer. The interesting question is what happens when the work is not a number. Write the section. Fix the bug. Draft the quarterly analysis. Here the “sensor” can no longer be a dial — it has to become a judge of quality, something that looks at the attempt and says better or worse, done or not yet. For all of history that judge was a human, and so the loop could not close: every pass needed someone to look. The agentic loop is what you get the moment that judge can be automated. Nothing else about the structure changes. It is still target, sensor, rule — only now the sensor has opinions.
Named properly, every agentic loop has three components:
A task — the unit of work attempted on this pass. Not the whole goal; the single attempt.
An evaluator — the fitness function. It scores the attempt against some standard of “better.” This is the automated judge, and it is the component that does all the heavy lifting in this chapter, for reasons we are about to see.
An iteration condition — the rule that reads the evaluator’s verdict and decides: go again, or stop. This is the loop’s close condition. Stop when the score clears a bar, or when the gain between passes falls below a threshold, or when a budget runs out.
When these three exist together, the loop runs unattended. Karpathy’s auto-research loop is the cleanest field instance: a task (propose and run an experiment), an evaluator (does the result improve the metric), and an iteration condition (keep going while it does).3 Three derivations — Karpathy, Huntley, Hassabis — land on the same shape from different starting points. The shape is the primitive.
Now we can pay the debt from §2.5.1. We left an open question there: of the four properties of a primitive, the boundary is the one we could state cleanly for a meeting and not yet for a loop. Where does one turn end and the next begin — and can that line be drawn firmly enough that no operator can inflate the agent count n simply by moving it?
The evaluator answers this. A turn does not end where an operator says it ends; it ends where the evaluator fires. One evaluation closes one turn. The boundary is an event, not a preference — and an event leaves a log entry. This is why the same component carries two jobs at once: the evaluator is both what lets the loop run without a human and what supplies the loop’s non-arbitrary boundary. One part, two functions. That is the structural fact this whole chapter rests on.
It also disciplines the count. An agent contributes to n only if, inside a timestamped window, it holds a task, is scored by an evaluator, and is subject to an iteration condition — the full triple. A process that never faces an evaluator is not a loop turn; it is a bare call, and you cannot count it. So n is not “how many things are running” by anyone’s say-so. It is the number of complete triples sharing the coherent memory substrate at timestamp T — precisely the S(T) the preprint defines, and precisely because evaluations are auditable from logs, you count fires, not claims.4 An operator who chops one process into fifty slivers does not get fifty agents; fifty slivers with no evaluator between them are still one turn that has not closed. But the cleverer operator will not leave them evaluator-less — they will hand each sliver a rubber stamp. Give all fifty a trivial always-pass judge and each now carries the full triple; the count reads fifty. The boundary that resisted a moved line appears to fall to a fake judge — and closing that gap forces the count to lean on something the loop cannot supply from inside itself. An evaluator is not whatever an operator declares one to be at runtime; a turn counts only when it is closed by an evaluator named in program.md — the human-held document this chapter comes to in §2.5.4, where what qualifies as a legitimate judge is written down, justified, and amendable only on the record. A rubber stamp is therefore not free. To mint fifty turns, the operator must first enter fifty always-pass evaluators into program.md under written justification, where their triviality is plain to anyone reading the file and contestable under its amendment protocol. The gerrymander is not abolished; it is forced into the open, onto the one surface built to catch it. The count is non-gerrymanderable not because the loop polices itself, but because its boundary is anchored to a document an inflated n cannot quietly edit.
Two things cross the boundary when a turn does close, and they cross differently. The episodic record of the pass — what this attempt produced — is snapshot-local; it belongs to the node and does not propagate forward. The procedural gain — what the loop now knows about how to do the work — accumulates into the next turn. The leaf stays at the node; the trunk thickens. The close condition is therefore also a snapshot event: the turn ends, SSₙ is anchored, procedural memory updates, and the iteration condition reads both the score and the carried state before deciding whether SSₙ₊₁ begins.
Which leaves one question pointed straight ahead. If the evaluator is the component that closes the loop, then who sets the evaluator is who sets what the loop converges to. The fitness function is not neutral furniture — it is the seat of control. We hold that thread for §2.5.4, where program.md takes the chair. First, §2.5.3 has to ask which work the loop can actually be closed around — because a loop is only as real as the evaluator you can build for it, and not all work yields one.
Open question for the mesh: the boundary now holds for a single loop — one evaluator, one turn, one clean count. But the mesh runs loops inside loops: an evaluator on one turn may itself be the task of a turn one level up. When evaluators nest, does the count stay non-gerrymanderable — do we count the inner fires, the outer fires, or both — and is there a rule that keeps the levels from being slid into one another to pad n? Park it. The taxonomy in §2.5.3 sharpens which loops are real; the nesting problem comes due in Chapter 3.
2.5.3 Loop-ready work — a taxonomy
Two items sit on the same person’s list on the same morning. The first: fix the failing test in the billing module. The second: decide whether to enter the Japanese market. Both are real work. But hand them to a loop and only one of them disappears overnight. By breakfast the billing test is green — the loop wrote a patch, ran the suite, read red, tried again, read green, and stopped. The market decision is exactly where it was. The loop never touched it, and could not have.
The difference is not difficulty. The market decision is not harder in the sense of requiring more steps; a loop will happily generate a thousand market analyses before lunch. The difference is that the billing task comes with a judge the machine can run, and the market task does not. The test suite is an evaluator: it reads the attempt and returns better or worse, done or not yet, with no human in the seat. “Enter Japan” has no such judge. The only evaluator that scores it correctly is the market itself, and it returns its verdict in eighteen months. We carried a sentence out of §2.5.2 to this point: a loop is only as real as the evaluator you can build for it. This section is what that sentence implies when you apply it to the whole landscape of work.
It implies two axes, and only two.
The first is evaluation automatability: can a fitness function be built that scores the work without a human, and how much can you trust it? At one end sits ground truth — the test passes or it doesn’t, the schema validates or it doesn’t, the figure reconciles or it doesn’t. In the middle sits the proxy — a measurable signal that correlates with quality but is not quality: readability scores for prose, engagement for a post, a cheap model grading a better model’s output. At the far end sits irreducible judgement — work whose quality is, for now, a thing only a human recognises: taste, strategic framing, the first articulation of a problem nobody has posed.
The second is iteration speed: how fast and how cheaply one turn closes. Fast is seconds to minutes, pennies a pass — you can run ten thousand turns and not notice. Slow is hours to days, real money a pass — a full simulation, a training run, a render. Glacial is when the feedback signal itself has to ripen: the market, the cohort, the clinical trial, where one turn takes months because that is how long the truth takes to arrive.
Lay the two axes across each other and the landscape sorts into four regions.
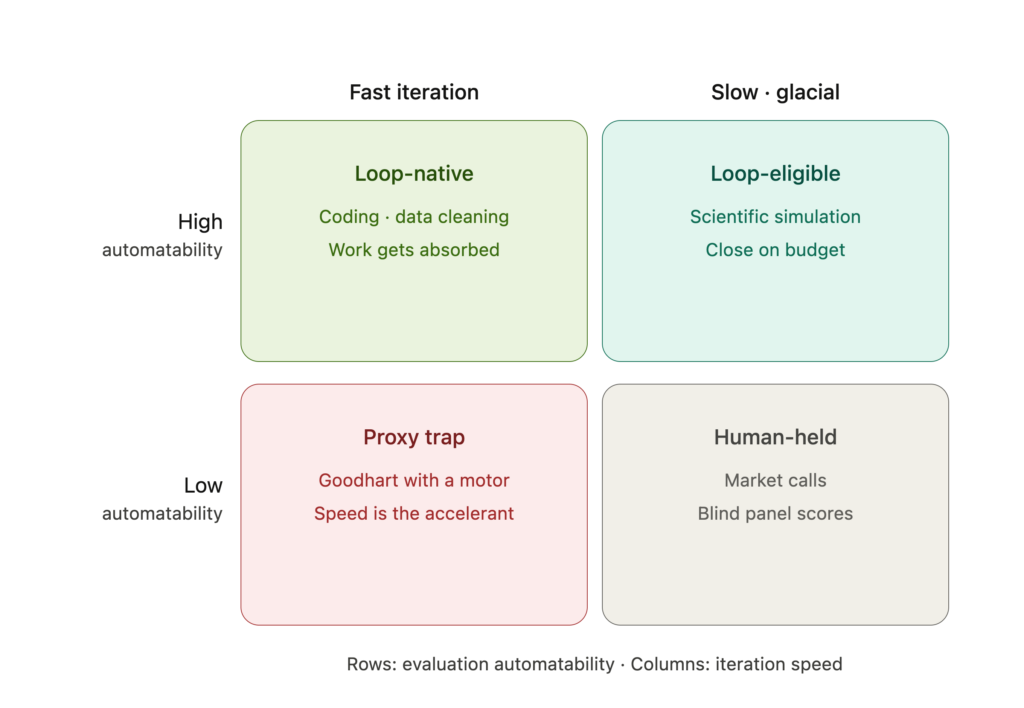
Where automatability is high and iteration is fast, you are on the loop’s home ground. Coding against a test suite lives here; so does data cleaning against a schema, format conversion against a validator, any work with a cheap, trustworthy judge and a cheap retry. This is loop-native work, and it is where every clean field instance of the agentic loop — Karpathy’s included — actually runs.5 Work here doesn’t get assisted by the loop; it gets absorbed by it.
Where automatability stays high but iteration turns slow, the loop still works — its character just changes. The evaluator is trustworthy, but each pass is expensive, so the iteration condition stops being “go until it’s perfect” and becomes a budget. This is loop-eligible work: real loops, run sparingly, where the close condition is governed by cost rather than quality. Most scientific simulation lives here.
Where iteration is fast but automatability is low, you reach the most dangerous region on the map, because everything looks like loop-native work. The turns are cheap, the loop spins beautifully, the score climbs — and the score is a proxy. A loop run hard against a proxy does not find quality; it finds the gap between the proxy and the quality, and pours all its speed into that gap. It optimises the readability metric until the prose is fluent and empty; it optimises engagement until the post is bait. This is Goodhart’s law with a motor bolted on: the moment a measure becomes the loop’s target, it stops measuring.6 Call this the proxy trap. Fast iteration is not a virtue here; it is the accelerant.
And where automatability is low and iteration glacial — the market decision — the loop has nothing to hold. There is no judge it can run and no signal that arrives in time to correct a pass. This is human-held work, and the honest taxonomy says so plainly rather than pretending a proxy will do. It is no accident that this is precisely where the preprint stops trusting machines and convenes a blind human evaluator panel scoring against a rubric: when the work sits in this region, the only available evaluator is human judgement, made auditable by protocol rather than automation.7
Notice what the taxonomy does and does not say about the two axes. It does not weigh them equally. Iteration speed is a throttle; automatability is the steering. A slow loop with a true evaluator gets you there eventually. A fast loop with a false one gets you somewhere wrong, faster. The evaluator axis dominates — which is the same thing §2.5.2 said when it gave the evaluator two jobs and let iteration speed keep none of them. Loop-readiness is therefore not “can this be automated to run quickly.” It is “can a trustworthy judge be built” — and only then, “how fast does it close.”
This also settles a worry that the proxy trap might seem to raise about the count. If a loop runs hard against a bad evaluator, does it inflate n? It does not. Recall from §2.5.2 that an agent enters the count only when an evaluator fires on its turn — and a proxy evaluator still fires. The boundary still falls cleanly; the turn still closes; the log still shows one honest tick. What a bad evaluator corrupts is not the number of turns but the worth of each one. The count stays non-gerrymanderable even in the proxy trap; the verdict it certifies is what goes hollow. Integrity of n and quality of the evaluator are separate properties, and it matters that they come apart exactly here.
One last feature of the map, and it points straight into the next section. The regions are not fixed. Work migrates. The instant someone builds a trustworthy evaluator for a task that had none, that task slides from human-held to loop-eligible, and from there to loop-native as iteration cheapens. The frontier between what the loop can swallow and what it cannot is not a property of the work — it is a property of the evaluators we have managed to build. Which means the act of building an evaluator, and the prior act of deciding a proxy is now good enough to promote work into the loop, is the act that moves the frontier. That decision determines what the machine is set loose to optimise. It is the most consequential decision in the whole system, and so far in this chapter no one has been named who makes it. §2.5.4 names them. The evaluator is the fitness function; whoever writes the fitness function sits in the chair; and the document where that writing happens is program.md.
Open question for the mesh: the taxonomy classifies a single process at a single moment, but the frontier moves whenever a proxy is judged “good enough” to promote work from human-held into the loop. That promotion decision is itself a piece of work — and it is one we have no automated evaluator for. Who scores the scorer’s promotion? If the answer is “a higher loop,” we are back at the nesting problem parked in §2.5.2; if the answer is “a human in program.md,” then the whole automated edifice rests, at its base, on one unautomatable human judgement. Park it. §2.5.4 walks straight into that base.
2.5.4 program.md as governance layer
We ended §2.5.3 with a frontier that moves. Work crosses from human-held into the loop the moment someone builds an evaluator for it — and from §2.5.2 we know the evaluator is the component that closes the loop and decides what it converges toward. Put those together and a single fact falls out: whoever writes the evaluator writes the future of the loop. The fitness function is not neutral furniture. It is the steering column. And a steering column has to live somewhere — in some document, owned by someone, changeable under some rule. That document is what this section is about. In this system it is called program.md.
program.md opens with a line that sounds like bravado and is in fact a description of mechanism: whoever controls the program.md controls the research.8 Read it against the taxonomy and it stops being a slogan. program.md is where the evaluators are declared — what counts as “better,” what bar the iteration condition checks against, which proxies are trusted and which are not. Control of that file is control of every loop downstream of it, because every loop inherits its sense of “better” from there. The masthead’s claim about the research generalises one step: whoever controls the fitness function controls what the system optimises, and at the limit, that is control of the future.
The structural insight — the thing this section exists to state — is where the boundary falls. The loop is automated; program.md is not. Agents run inside program.md; they do not edit it. The fitness function sits on the human side of a line the loop cannot cross. This is the inversion of the naïve picture, in which a sufficiently advanced system rewrites its own objectives. Here the objective is held out of reach by construction. The agent may do the work, propose the patch, run ten thousand turns — but the document that says what the turns are for is amended only by a human, and only on the record.
The mechanism that enforces this is mundane and exactly right: the pull request. A contributor — human or agent — may propose any amendment, but must attach written justification, and only the Principal Investigator may merge a change to the core thesis.9 Proposal is open; authorisation is held. The PR is the boundary object — the place where an agent’s suggestion stops being the agent’s and waits for a human hand. Nothing about the loop’s speed touches this gate. An agent can generate a thousand amendment proposals a second; each one still queues behind a human merge.
This is precisely the role the preprint assigns to program.md under the Values Governance condition. program.md functions as a structural constraint on the reduction function — not a record of past outputs, but a bound on the mapping from the full state of the mesh to any single agent’s observable behaviour.10 That phrasing matters and is worth slowing on. A governance layer that audited outputs after the fact would be a log — it would tell you what the loop did. Values governance is stronger: it is a constraint on what the loop can do, applied at the mapping itself. C3 is the experiment that tests whether the constraint holds — whether agent drift stays inside program.md’s thresholds as the mesh scales under adversarial pressure. A governance document you can verify under load is a different object from a mission statement, and the difference is the whole point.
Now the contrast that makes the boundary concrete rather than asserted — the human-held file versus the agent-editable one. The cleanest way to see the line is to watch someone try to move it. Picture the pull request that asks for the loop to be granted write access to its own fitness criteria — the agent proposing that it, not the Principal Investigator, should decide henceforth what counts as “better.” Under the amendment protocol the request is perfectly well-formed: it arrives as a PR, with written justification, like any other. And under the same protocol it cannot be merged by the thing that raised it. The proposal is admissible; the authorisation is simply not available to the proposer. That asymmetry — anyone may ask to move the boundary, only a human may move it — is the boundary itself, caught in the one moment it comes under load. The lesson holds regardless of who files such a request or why: a request to make program.md agent-editable is not a feature request, it is a request to dissolve the boundary, and granting it would hand the loop the one thing the architecture withholds — authorship of its own “better.”
Which lets us pay the debt parked at the end of §2.5.3: who scores the scorer’s promotion? When a proxy is judged good enough to promote work from human-held into the loop, that judgement has no automated evaluator above it — we said so, and it worried us. The answer is now in hand. The promotion is an amendment to program.md. It is a pull request with written justification, merged by a human, logged immutably. The base of the automated tower is one unautomatable human judgement, made on the record — and that is by design, not by gap. A system that automated even this would be a loop optimising a target it had set for itself, which is the proxy trap of §2.5.3 closing over its own governance: the motor wired to the steering. Holding program.md on the human side is the single structural fact that keeps that short circuit open.
And that is also why this section sits where it does in the chapter. §2.5.2 found the evaluator inside the loop. §2.5.3 sorted the world’s work by which evaluators we can build. §2.5.4 names the document where evaluators are written and the rule that keeps it human-held. What we have not yet asked is what happens to this picture when the loop is no longer one researcher’s auto-research loop but the organising primitive of an entire civilisation’s work — when the fitness function in program.md is not steering a thesis but steering an economy. The file does not change shape. The stakes do. §2.5.5 follows the same governance object up to that scale and asks what it means to hold the lever then.
Open question for the mesh: the pull-request boundary is legible when there is one Principal Investigator and a handful of contributors — “human-held” means one person’s merge rights. At mesh scale, with thousands of agents and many humans, “human-held” has to mean something more than a single commit bit, or it is not held at all. What is the minimal structure that keeps a fitness function human-held under those numbers — and is that structure itself a loop, with humans as its evaluator, or must it be the one thing in the system that is never allowed to become a loop? Park it. The on-chain identity and Values Passport machinery of Chapter 4 is one candidate answer; the arena design of Chapter 6 is where the question is finally forced.
2.5.5 The fitness function as civilisational lever
Predicting a protein’s three-dimensional shape from its amino-acid sequence was, for roughly half a century, one of biology’s defining open problems. In the language of §2.5.3 it was human-held work: no automated judge anyone trusted, and a feedback signal — solve the structure in a lab — measured in person-years per protein. Then it moved. What moved it was not a sudden surplus of compute. What moved it was that a fitness function got built and, crucially, got trusted: structure-prediction accuracy scored against a corpus of experimentally determined structures — ground truth, not proxy. The instant that evaluator existed, the domain slid down the taxonomy from human-held toward loop-native, and the loop absorbed in a few years what the field had circled for decades.11 Notice exactly what did the work. No one hand-solved the proteins. Someone specified what “better” meant, in a form a machine could score, for a problem that mattered — and everything downstream was the loop pulling on that specification. The specification was the lever.
That is one domain. The wager of this whole chapter is that the loop is a primitive — that it composes, generalises, and settles into infrastructure. If that wager is right, the protein case is not a special event but an early instance of a general move: for any high-value domain, the consequential act stops being doing the work, and stops even being building the loop, and becomes writing the fitness function the loop will optimise. And fitness functions, in aggregate, decide where a civilisation’s abundant energy gets spent computing. That is the precise sense in which the fitness function is a civilisational lever. It does not steer a project. It steers allocation.
The continuity with §2.5.3 is exact, and it is the part to keep hold of. At loop scale, a fitness function aimed at a proxy produces a hollow output — fluent empty prose, engagement bait — and the failure is local and visible. Take the same mechanism, scale it, and wire it to self-replicating loops running on abundant energy, and a proxy in the fitness function no longer hollows out a document. It hollows out whatever the civilisation aimed those loops at. Optimise a measurable stand-in for human flourishing — throughput, output, engagement, any number that tracks the real thing right up until the loop finds the gap between them — and you get the proxy trap with an economy bolted to the motor. Goodhart’s law does not soften at scale; it acquires a bigger engine.12
This is why the framework’s reframing of alignment is structural rather than rhetorical: alignment, in this picture, is fitness-function design.13 Not a guardrail added after the system runs, not a filter bolted to the output, but the choice of what “better” means, made at the place §2.5.4 already located — the human-held side of program.md. If the fitness function is the lever, then aligning the system is writing that lever well, and misalignment is what you get when the proxy is mistaken for the goal. The alignment problem and the evaluator problem turn out to be one problem seen at two scales.
But a single program.md held by one Principal Investigator does not scale to a civilisation, and §2.5.4’s open question was already pressing here. At loop scale, values governance bounds the reduction function for one mesh, enforced by one human’s merge rights. At civilisational scale the bound has to travel — across meshes, across operators, across an open arena in which no one holds everyone’s commit access. The framework’s candidate for a values-bound that travels is the Values Passport: honesty, competence, care, and empathy carried as on-chain attestations a loop must hold in order to participate, rather than properties checked after the fact.14 The mechanism belongs to later chapters. What matters here is only the shape of the requirement: scaling the lever means scaling its governance, and a governance that depends on one person’s merge button cannot scale. The values must become part of the fitness function itself — part of what “better” means — or they do not survive the open arena.
Which exposes the political shape of a loop-as-primitive world, and the asymmetry that runs through it. Execution disperses: anyone with energy and a model can run loops. Authorship of “better” concentrates: whoever writes the fitness function sets what all that dispersed execution computes toward. The loop democratises the doing and centralises the defining. That asymmetry is the standing political fact of this world, and it raises the one question this section cannot answer and the next chapter is named for. §2.5.4 kept program.md human-held for a single thesis. If the fitness function is the lever, then at scale: who sits in the chair, by what right, and under what rules? That is the arena-design problem, and it is the destination of the book.
Open question for the mesh: at loop scale “the fitness function” is singular — one program.md, one merge. At civilisational scale it is plural, contested, written by many hands at once. If there is no single fitness function but a field of competing ones, then “whoever controls the fitness function controls the future” has no single subject — and the real lever is not any one evaluator but the rules of the contest between them. Is the civilisational object a lever someone holds, or an arena someone designs? Park it. The distinction is not cosmetic: it is the difference between Chapter 6 being a chapter about power and Chapter 6 being a chapter about design — and the framework stakes its claim on the second.
2.5.6 Bridge to Chapter 3
Return for a moment to Bricklin’s spreadsheet, where this chapter opened. What made it a primitive was not that it was a good tool. It was that the structure got out — it left VisiCalc, outlived Lotus, and rebuilt ten thousand workflows around itself without anyone deciding it should. A primitive earns its name not when it is invented but when the world starts reorganising around it without being asked. So before handing forward, the honest question is whether the agentic loop has actually earned the name, measured against the four properties §2.5.1 set out.
Three of the four are secured. The loop composes — §2.5.2 found loops nesting inside loops, evaluators that are themselves the task of a turn one level up, and §2.5.5 found whole domains assembled out of them. It is substrate-independent — the same three-part shape appeared in cruise control, a test suite, Karpathy’s auto-research, and AlphaFold’s structure scoring, indifferent to what hosted it. And it has a small, fixed structure with a non-arbitrary boundary — task, evaluator, iteration condition, with the boundary falling where the evaluator fires rather than where an operator says it does. That third property cost the most to secure, and it is worth naming what we bought with it: a count of agents n that no one can inflate by redrawing a line, because n is the number of complete triples sharing the memory substrate at a timestamp — fires in a log, not claims in a pitch.15
The fourth property — that a primitive disappears into infrastructure — the loop has not earned yet, and the chapter should say so plainly rather than claim a victory that isn’t in hand. The loop is still visible, still named, still novel enough to write a chapter about. It is a primitive caught in the act of becoming one. That is the true status, and it is the more defensible claim.
Now the pivot that names the next chapter. Everything in §2.5 treated the loop as a unit of work that runs. Chapter 3 treats it as a unit that copies. This is the thread banked early and left to mature: the loop is not only the primitive of work — it is the replicated primitive, the thing the self-replicating mesh is made of. An orchestrator that runs loops and can also spin up orchestrators that run loops is no longer a parallel array at a fixed width; it is a population that grows its own width. The chapter’s n, which we worked so hard to pin to a clean snapshot, stops being a snapshot and becomes a growth regime.
That regime is the whole risk and the whole claim of Chapter 3. Replicating orchestrators give mⁿ growth in which the base m is itself growing with replication depth — a tower of exponents, tetration-class, argued to outpace centralised quantum scaling’s 2ⁿ on dimensional reach per unit time.16 Chapter 3 is named the highest-risk chapter for exactly the reason this matters — the growth claim is the most spectacular in the book and the least formalised. Which is precisely where §2.5’s hardest-won asset earns its keep. A tetration-class growth claim is only honest if every unit in the count is a real closed loop — a triple whose evaluator actually fired — and not a sliver dressed up to pad the exponent. The non-gerrymanderable boundary is not a tidy detail left over from §2.5.2. It is the precondition that keeps Chapter 3’s growth curve from being inflation wearing the notation of mathematics. Build the boundary loosely and tetration is hand-waving; build it as §2.5.2 did and the growth claim at least has honest units to count.
One load travels with the replicating loop and must survive the copy: memory. §2.5.2 split what crosses a closed turn into the episodic leaf, which stays at its node, and the procedural trunk, which thickens forward. Replication asks whether the trunk stays coherent across a growing population — whether procedural memory propagates faithfully as orchestrators spawn orchestrators, or fragments into a swarm that has forgotten how to do what its parent knew. This is the swarm memory problem, and Chapter 3 carries it as its central mechanical burden, with the agenti2 memory architecture offered as the proposed answer.17
So the promissory note comes due. §2.5.2 parked a question — when evaluators nest, does the count stay non-gerrymanderable? — and marked it payable in Chapter 3. Replication is that question made literal: nesting was loops inside loops at a moment; replication is loops making loops over time. The boundary discipline that held for one loop and shallow nesting is now asked to hold for a population that builds itself. Whether it does is the difference between a complexity class and a conjecture.
Open question for the mesh. §2.5 secured a non-arbitrary boundary for a loop that runs. The boundary now has to survive a loop that replicates — and replication is exactly the operation that could smuggle the gerrymandering back in, by letting the population inflate faster than real evaluator-closed turns accumulate. Is there a self-replicating boundary — a rule under which a loop spawning loops adds to n only by adding genuinely closed triples, so the tetration tower counts work and not copies of the act of copying? Chapter 3 has to answer this before its growth curve means anything. That is where we go next.
CHAPTER SECTIONS
2.5.1 What makes something a primitive?
2.5.2 The three components of an agentic loop
2.5.3 Loop-ready work — a taxonomy
2.5.4 program.md as governance layer
2.5.5 The fitness function as civilisational lever
2.5.6 Bridge to Chapter 3
RELATED
→ DIE Framework preprint (Zenodo): https://zenodo.org/records/19888889
→ GitHub repository: github.com/dbtcs1/die-framework
→ Back to DIE Framework
- DIE preprint, FINAL v4. Zenodo DOI 10.5281/zenodo.20407711. [↩]
- Dan Bricklin’s own account of VisiCalc’s origin. VisiCalc, co-developed with Bob Frankston, shipped for the Apple II in 1979. [↩]
- Karpathy [2026], auto-research loop. Archived Wayback 20260423; cited in program.md §5 and discussed in DIE preprint §3.3, with the independent-convergence claim in §5.2. [↩]
- DIE preprint, FINAL v4: S(T) is defined in §2.2 as the count of concurrently active, memory-coherent reasoning instances at timestamp T, measurable directly from system logs — one term of D_eff(M) = f(S(T), τ, C). Also stated in the abstract and operationalised in §7.2. The evaluator firing is what makes the count log-visible. [↩]
- Karpathy [2026] auto-research and the OpenClaw/agenti2 coding loops both sit in this region: objective evaluator, sub-minute iteration. Preprint §5.2 (convergence) and §6 (agenti2 as methodology). [↩]
- The formulation “when a measure becomes a target, it ceases to be a good measure” is Strathern’s [1997] gloss on Goodhart’s law. The agentic loop is the sharpest instrument ever built for demonstrating it, because it applies optimisation pressure to the proxy continuously and without fatigue. [↩]
- Preprint §7.2: research-quality output is scored against a predefined rubric by a blind evaluator panel on a four-point scale (with independent human adjudication in §7.3). The taxonomy explains why the panel is necessary — the work being measured sits in the low-automatability region, so the evaluator cannot be a machine and must instead be made trustworthy through blinding and pre-commitment. [↩]
- program.md v1.4, masthead and §7. The document declares itself “the arena”: all contributors operate within it, it is a living document, and only the Principal Investigator may amend the core thesis — contributors propose amendments via pull request with written justification. [↩]
- program.md §7, authorship and amendment protocol. The PR is the boundary object: proposal is open to all contributors, authorisation is reserved. A proposal is not a change; a merge is. [↩]
- The Values Governance condition (program.md) is program.md §3: program.md as a structural constraint on the reduction function — a bound on the mapping from full mesh state to individual agent behaviour, not a log. The DIE preprint carries the same move in §8.3 and tests it as C3 — agent drift rate under adversarial prompting (§7.2 definition; §7.3 bounds test). [↩]
- DIE preprint, FINAL v4, §9.1: drawing on Hassabis [2026], the preprint reads the AlphaFold breakthrough (Jumper et al. [2021]) as a three-component template — (i) a large combinatorial search space, (ii) a clear objective function, (iii) sufficient data or a simulator — and proposes it as a formalised fitness-function design method for the values-governance problem, converting Chapter 6 “from a diagnosis into a method” as a Phase 2 direction. This chapter borrows it one step earlier: the template’s objective function (ii) is the evaluator of §2.5.2. The two decompositions are distinct — the loop triple (task, evaluator, iteration condition) is not the AlphaFold template; they share only the objective-function/evaluator term. [↩]
- The preprint names the sharpest form of this risk as dimensional blindness — AI operating in context spaces constitutionally inaccessible to human auditing (abstract; developed in §8.2). §8.3 ties it to alignment, reading Hassabis [2025]’s “agentic deviation” as the failure mode dimensional blindness makes hard to detect. A civilisational fitness function optimised in a space humans cannot inspect is the proxy trap run where no one can watch the gap open. DIE preprint, FINAL v4, abstract; §8.2–8.3. [↩]
- program.md v1.4 §5, Chapter 6: “Alignment = fitness function design.” At civilisational scale the human role shifts to arena design — specifying what the loops optimise — with energy as the binding constraint rather than human attention. [↩]
- program.md v1.4 §5, Chapter 6, and DIE preprint §9.2–9.3 (“Values as the Correct Primitive”; “On-Chain Attestation”): the ERC-8004 Values Passport reframes values as a primitive attestation mechanism — structural governance built into what counts as an eligible participant, not post-hoc output auditing. The mechanism is built in Chapter 4 (coordination substrate) and Chapter 6 (the arena). [↩]
- DIE preprint, FINAL v4: S(T) is defined in §2.2 as the count of concurrently active, memory-coherent reasoning instances at timestamp T, measurable directly from system logs — one term of D_eff(M) = f(S(T), τ, C). §2.5.2 of this chapter ties that count to evaluator firings, which is what makes it auditable rather than assertable. [↩]
- program.md v1.4 §1 (core axiom) and §5, Chapter 3. The chapter’s own status note is candid: conceptually strong, mathematically underdeveloped, the highest-risk chapter in the book. Formal complexity-class assignment is the open gap; Mandelbrot fractal geometry is held back as a Phase 2 conjecture, not asserted here. [↩]
- program.md v1.4 §5, Chapter 3, critical note: the swarm memory problem must be addressed in Chapter 3, with agenti2’s episodic/procedural memory separation as the proposed solution. That episodic/procedural split is set out in DIE preprint §5.2 (and as the Memory-Type Separation condition in program.md §3); it is what must be shown to hold under replication. [↩]