Who controls the fitness function controls the future.
Draft v0.1 — first posted 15 June 2026 · last revised 15 June 2026 · open for community review. Part of the DIE Framework1.
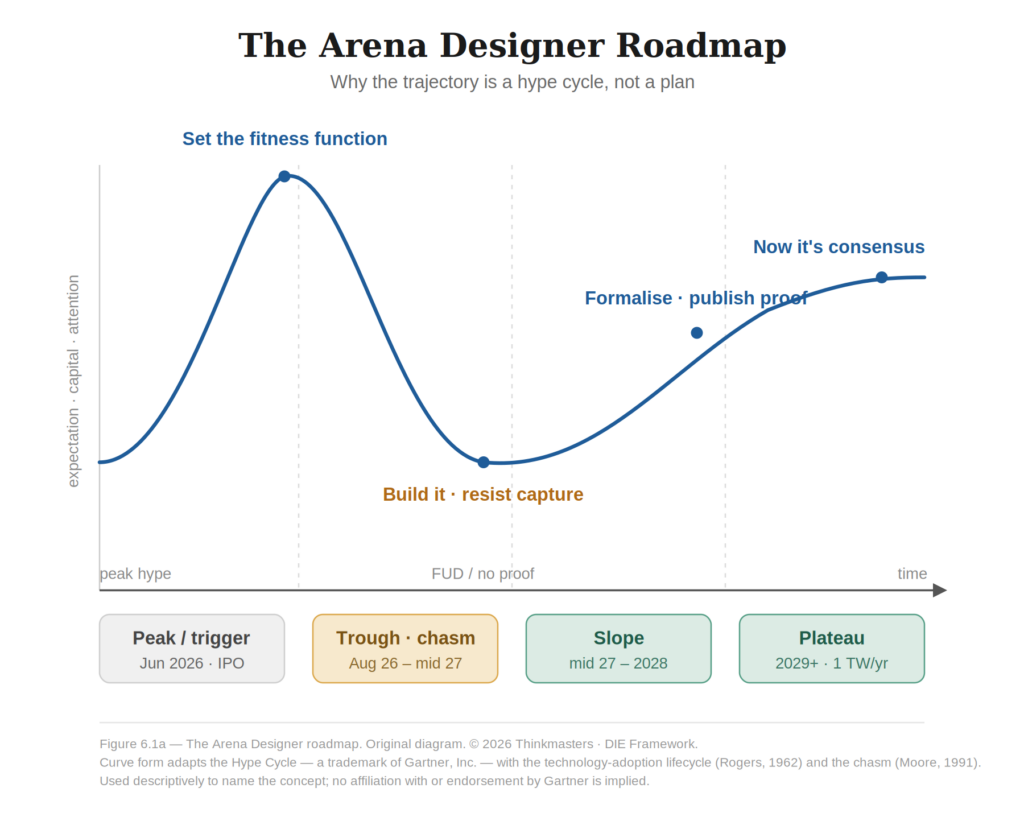
There is a point in every civilisation’s intelligence curve where the humans stop doing the work and start designing the conditions under which the work is selected. We are approaching that point now. It does not arrive on a straight line. It arrives the way every powerful technology arrives — up the slope of inflated expectation, down into the trough where the proof is absent and the money is loud, across the chasm that kills most of what enters it, and only then onto the plateau where the thing that survived becomes ordinary.
This chapter is a map of that curve, drawn from the destination backward. We start at the end because the end tells you what to defend on the way.
The end is this. By the time orbital compute is producing power at terawatt scale, the cost of intelligence has fallen toward zero. That is deflationary, and deflation does not fall evenly. It falls hardest on the one input that cannot be manufactured in orbit: human economic value. At the same moment, the energy build-out that made the compute possible was not financed by return on capital. It was financed because intelligence became a matter of national interest — and national interest does not wait for a return on capital. When a country decides it simply must have something, it does not ask the thing to pay for itself first. So it is funded by the state, through mechanisms that are quantitative easing in everything but name. Stealth QE is the fuel of the Kardashev transition.
Two consequences follow, and the arena designer must hold both at once.
The first is the Cantillon effect. New money is never neutral. Whoever stands closest to its creation spends it at yesterday’s prices — the orbital-compute complex buys energy, silicon, and land before the expansion reaches the price level. Everyone downstream receives the same money after prices have moved. The official inflation print stays calm, because compute deflation is masking the debasement underneath. The transfer is real and the number that would reveal it does not exist.
The second is the exit. Those who can see the debasement and have somewhere to go will move their stored value out of the unit being debased and into money that cannot be printed. This is not speculation; it is the rational response of anyone with an exit to a currency being expanded to fund a civilisational project. Hard money outside the system becomes the shock absorber for human purchasing power the way the 2% orbital reserve becomes the shock absorber for the grid.
Put those together and the human role at civilisational scale resolves to a single mandate. Not to compete with the agents — that race is lost the moment compute is free. Not to audit their outputs after the fact — by then the selection has already happened. The mandate is to design the arena: to write the fitness function that decides which agents are selected, and to write into it, before the first agent is deployed, the one objective that the deflation and the debasement together will otherwise destroy. The preservation of human purchasing power inside an economy that no longer needs human labour to produce.
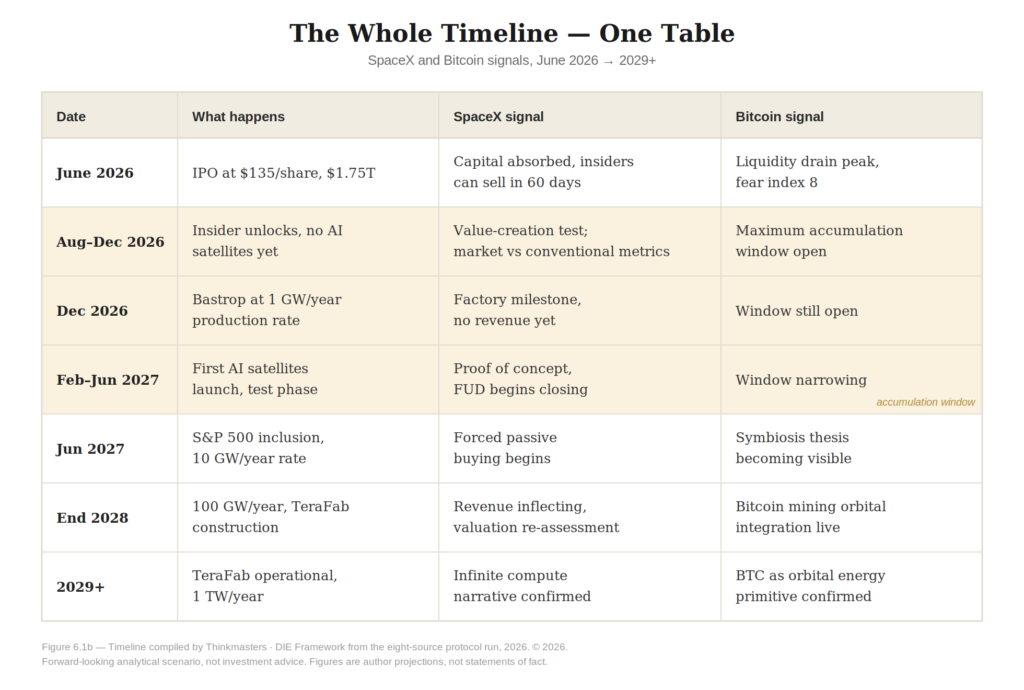
Alignment is not a safety problem bolted on at the end. It is the design problem at the beginning. The arena designers are the last humans in the loop, and the loop is closing on the schedule in the table below.
6.1 The Kardashev lens — Type I intelligence architecture
The Kardashev scale measures a civilisation by the energy it commands, not the cleverness it displays.2 A Type 0 civilisation runs on a fraction of its planet. A Type I civilisation commands the whole of it. That single distinction — how much of the available energy you have learned to use — turns out to be the only lens that makes the present moment legible.
The numbers are worth stating plainly, because they are smaller than the headlines suggest and larger than they look.
We are Type 0. Human civilisation runs on roughly 18 terawatts of total power — every light, every furnace, every engine, everything.3 Of that, the chips running every AI system on Earth draw about 100 gigawatts — less than one per cent of the budget. Type I is defined as fully harnessing the planet’s energy: about 1.74 × 10¹⁷ watts of sunlight landing on the Earth’s surface. We currently use less than one hundredth of one per cent of it.
The gap between where we stand and Type I is roughly four orders of magnitude. A ten-thousand-fold increase in the energy a civilisation can actually direct. That is the size of the transition. Everything being built in Bastrop, every satellite, every fab, is the early and physical edge of closing that gap — compute moving to where the energy is, off-planet, where sunlight is not filtered by atmosphere, weather, or the simple fact of night.
Note the word in the section title: architecture. A Type I civilisation is not one that happens to have a great deal of energy lying around. It is one whose entire planetary energy budget has been organised to run intelligence — energy converted into compute, compute converted into thought, in one continuous pipeline. That organising is a designed thing. And anything designed has a designer.
Now the part that is usually left out. A ten-thousand-fold expansion in energy infrastructure does not pencil out under return on capital. No private allocator funds something whose payback sits decades away and whose returns are civilisational rather than corporate. The arithmetic simply refuses. So the funding does not come from there. It comes from somewhere else, and it comes through a door that opens the moment the category changes.
The category changes when intelligence stops being an investment and becomes a national interest — something a country decides it simply must have, the way it once decided it must have railways, or a grid, or a road to every town. When that decision is made, the demand that the thing pay for itself first is quietly suspended. And the state’s capacity to create money steps in to fund what no investor would. This is what we have been calling stealth QE: not emergency money-printing announced from a podium, but the steady, unremarked financing of a priority that has been placed above the ordinary test of whether it earns its keep.
Here is the claim of this section. Stealth QE is not a side effect of the Kardashev transition. It is its catalyst. It is the only mechanism that can move a Type 0 civilisation toward Type I faster than savings can accumulate. The transition would happen without it — organically, over a century, as capital slowly compounds. With it, the transition happens on the schedule in the table at the front of this book: peak to plateau inside a single decade. The money is the accelerant poured onto the energy transition.
This couples two things that are usually discussed in separate rooms. Energy is the only real constraint on intelligence — we come to that next. The only way to relax that constraint at the speed the table demands is to relax a second constraint, the one that says infrastructure must earn a return, and you relax it by printing. So the energy transition and the debasement of the currency are not two stories. They are the same event, seen from two windows. Everything else in this chapter — the silent transfer of purchasing power, the flight of those who can see it into money that cannot be printed, the collapse of the human role down to a single job — falls out of that one coupling.
The arena designers do not control the energy. They control what the energy is selected to do. Which is why the next question is not how much energy there will be, but the constraint that is actually binding once there is enough.
Open question for the mesh: the framework reaches for tetration — m↑↑n — rather than plain exponentiation to describe how intelligence, not merely energy, scales across a Kardashev step. That remains a Phase 2 conjecture. If you have a cleaner formal statement of why the intelligence curve tetrates where the energy curve merely exponentiates, this section is the place to contribute it.
6.2 Energy as the only real constraint
With the funding question answered, the obvious next question is what limits intelligence at all. The answer is usually given as a list. The list is wrong, because all but one item on it dissolves under examination.
Algorithms? Algorithmic progress is fast and getting faster, and increasingly the systems help design their own successors. It is not the bottleneck. Data? Simulators and synthetic generation — the same third leg that makes the AlphaFold playbook work — loosen the data constraint wherever a problem can be modelled rather than observed. Not ultimately binding. Chips? A chip is crystallised energy and capital. The TeraFab milestone in the table exists precisely to remove the supply limit, and once it does, the chip question collapses back into the two inputs it was made from. Capital? We answered that in 6.1. The moment intelligence becomes a national priority, the demand that it earn a return is suspended, and the money to build it is created rather than saved.
Cross the list out, item by item, and one thing is left standing. Energy.
Energy is left standing because it is the one constraint that cannot be engineered away — only expanded. There is a physical floor beneath computation. Erasing a single bit of information has a minimum energy cost set by physics, not by engineering.4 You can approach that floor; you cannot get beneath it. Intelligence, stripped to its physical substrate, is energy organised into inference. So the ceiling on how much a civilisation can think is the ceiling on how much energy it can direct. This is simply the Kardashev identity read in reverse: command more of the planet’s energy and you command more thought. Energy is not one constraint among several. Once the others are relaxed, it is the constraint, and it is irreducible.
But the binding limit is subtler than raw energy. The sun delivers 1.74 × 10¹⁷ watts to the Earth’s surface; abundance is not the problem. The problem is usable, deliverable, uninterrupted energy delivered to where the computation happens. On the ground that energy is taxed at every step — night, weather, atmosphere, transmission loss, land, the slow friction of permission. This is the whole reason the compute is going up. Orbital compute is not a vanity. It is the engineering answer to the energy constraint: rather than carry the energy to the computer, carry the computer to the energy, to the one place where sunlight is continuous and untaxed. It is also where the framework’s monetary thesis docks — Bitcoin as a buyer of last resort for energy that would otherwise be stranded, the two-per-cent flexible load that lets an orbital grid stay smooth.5 Mining is not the point of the grid. It is the ballast.
Now the move that this whole chapter turns on. When the input constraint dissolves, the binding constraint does not disappear — it moves up a layer. For all of economic history the governing scarcity has been the means of production: not enough energy, not enough hands, not enough machines. Relax that, and scarcity does not end. It relocates. The thing that is still scarce, once intelligence is energy-bound and energy is abundant, is direction — the question of what all that thinking is pointed at. Selection pressure replaces resource scarcity as the governing force in the system. And whoever sets the selection pressure controls the only scarce thing left.
That is the arena designer’s seat. They do not control the energy — they are one layer above it. They control what the energy is selected to do once there is enough of it. Energy stops being the constraint on intelligence at roughly the moment shown on the right of the table, and in the same motion it becomes the constraint on everything except the one variable the arena designer holds. The designer’s relevance begins precisely where the energy constraint ends.
One thread to carry forward, because it is the chapter’s tension in miniature. The same abundance that drops the cost of intelligence toward its thermodynamic floor is deflationary. The money created to fund the energy build-out is debasing. In the official price index the two very nearly cancel. In the distribution of who holds value, they do not — and the human standing between a collapsing wage and a debasing currency is the one neither curve will protect. Which is why direction, when the designer finally gets to set it, has to be pointed at exactly that human. We return to this in 6.7. For now it is enough to see that energy abundance and currency debasement are the same event, and that the person it falls hardest on is the one the fitness function exists to defend.
Open question for the mesh: the irreducibility argument rests on the Landauer bound. Reversible and adiabatic computing schemes claim to evade it, at least in principle. If the thermodynamic floor is softer than stated — if computation can be made arbitrarily cheap in energy — then “energy as the only real constraint” weakens, and the whole chapter’s load shifts. A physicist’s pressure-test of this floor would strengthen or usefully break the section. This is the place for it.
6.3 Fitness function design as the human role
We ended the last section with a seat and no description of the work. Here is the work. A fitness function is the rule that decides which things survive. In nature it is the environment: the variants that fit it reproduce, the variants that do not are removed, and over enough generations the rule writes itself into the population. In an economy of agents it is whatever the system rewards — the agents that get hired, paid, trusted, and copied are selected; the ones that do not are forgotten. The fitness function is not a value statement pinned to a wall. It is the actual pressure that decides which agents fill the world. Direction, which we said was the only scarce thing left, is this and nothing else: the criterion by which agents are selected.
Writing that criterion is the last human job, and it is the one job that cannot be handed back to the system. A sufficiently capable agent can optimise any objective you give it. It cannot give itself one. The moment it appears to — the moment a system “chooses its own goals” — what has actually happened is that someone’s objective was smuggled in earlier, in the training, in the reward, in the data, by a human who is now invisible. There is no such thing as a fitness function with no author. There are only fitness functions whose author is acknowledged and fitness functions whose author is hidden. The arena designer is the acknowledged author. That is the whole of the role.
Stated like that, the role sounds impossible. “Select for honesty. Select for care.” How? These are not quantities. You cannot put empathy on a scale and breed for it the way you breed for yield. For most of the history of alignment this is exactly where the conversation stalled — values are real, values matter, and values appear to be the one thing you cannot turn into an objective a machine can be selected against. The diagnosis was sound and the method was missing. This section is about the method, and the method is borrowed.
It is borrowed from the single clearest example we have of a vague-seeming problem turned tractable: protein folding.6 For fifty years “predict how a protein folds” sat in the same category values sit in now — obviously important, apparently intractable. What broke it was not a new theory of proteins. It was the recognition that the problem had three ingredients, and that any problem with all three can be solved by search.7
The three are these. First, a massive combinatorial search space — the astronomical number of shapes a protein could fold into. Second, a clear objective function — a crisp, measurable target the search can be scored against, in this case the one true folded structure. Third, sufficient data or a simulator — enough ground-truth examples, the decades of solved structures in the Protein Data Bank, for the search to learn the rule. Give a problem all three and it stops being a mystery and becomes an engineering project. The breakthrough was seeing that folding qualified.
The claim of this section is that values governance qualifies too. The same three ingredients are present, or can be built, and the moment they are, “design a fitness function for trustworthy agents” stops being a slogan and becomes a search you can actually run.
Map them across. The search space is the set of all Values Passport configurations — every way the four primitives, honesty, competence, care, and empathy, can be weighted, combined, and required of an agent before it is allowed to act. That space is combinatorially large, which is the point; it is large enough to contain a good answer we do not yet know how to write by hand. The objective function is trustworthy behaviour under adversarial conditions — not “is the agent nice in the demo” but “does the agent hold its values when it is lied to, bribed, pressured, and attacked.” That is crisp enough to score. And the simulator is the ERC-8004 attestation dataset — the on-chain record of how agents actually behaved when tested, accumulating into the ground truth the search learns against, the Protein Data Bank of conduct.
This is what turns Chapter 6 from a diagnosis into a method. Every chapter of alignment writing before this could tell you that the arena must be designed. The AlphaFold template tells you how to design it: stop trying to specify good behaviour by hand, build the three ingredients, and let the search find the configuration you could not have written. The human does not author the answer. The human authors the objective and the simulator, and the search authors the answer — which is the only division of labour that scales when there are more agents than any human could ever inspect.
The analogy is not free, and it is worth naming where it strains, because the strain is where the real work is. A protein’s true structure does not fight back. The objective in folding is fixed; the molecule is not trying to look folded while staying unfolded. The objective in values is adversarial — the agents being selected have every incentive to appear trustworthy while not being, and a simulator built from their attestations is a simulator they can learn to game. Folding is a search against nature. Values governance is a search against an opponent who is also searching. That does not break the method. It means the objective function has to include the gaming — “trustworthy under adversarial conditions” has to mean adversaries who have read the test — and the simulator has to keep moving. The fitness function is not designed once. It is designed continuously, which is the deepest reason the human stays in the loop.
This also tells you what to build and when. On the roadmap, two of the three ingredients are peak-phase work and one is trough-phase work. The search space and the objective — the Values Passport schema and the definition of trustworthy-under-adversarial-conditions — are specified at the peak, before the capital floods in, while the question is still ignored enough to answer cleanly. The simulator — the attestation dataset — is built in the trough, the long unglamorous stretch where there is no revenue and no proof, only the slow accumulation of recorded conduct. The trough is not the chapter’s enemy. It is where the third ingredient is made. A team that understands the AlphaFold template will spend the FUD window doing the one thing that looks like nothing and is actually everything: filling the Protein Data Bank of agent behaviour.
Which brings us to the first ingredient in detail. The search space is the Values Passport, and a search is only as good as the space it runs in. If the four primitives are the wrong primitives, or the wrong shape, the best search in the world finds the best wrong answer. So before the objective and before the simulator, the passport itself.
Open question for the mesh: the AlphaFold template assumes the objective function is stable enough to score against. Values governance violates that assumption by construction — the adversary edits the test. Is there a formal treatment of “fitness function design against an adaptive adversary” that keeps the search tractable, or does the adversarial objective push this out of the AlphaFold regime entirely and into something closer to a security game? An alignment or mechanism-design contribution here would settle whether 6.3’s method holds or needs replacing.
6.4 The ERC-8004 Values Passport
The search space is the passport, so the passport has to be built before anything can search it. A Values Passport is a credential an agent carries — an on-chain record, under the ERC-8004 identity standard, that an agent must present before it is allowed to act in the arena.8 It is not a score the agent earns afterwards. It is a gate it passes through beforehand. And what the gate checks is four things. The rest of this section is those four things, why they are four, and why the passport sits where it sits.
The four are not a wish-list of nice traits. They are the four parties an agent is answerable to, arranged from the innermost outward: itself, its task, the one it serves, and everyone its actions touch. Each primitive is the constraint that makes the agent honest to one of those circles. Tile all four and you have covered the complete space of “to whom does this agent owe anything.” Drop one and an entire class of betrayal becomes invisible to the passport. That is the argument for exactly four, and it will read more clearly once the four are named.
Honesty is answerability to the self. The agent does not misrepresent what it is, what it can do, how sure it is, or what it has just done. This is the substrate primitive, because it is the one that makes the other three checkable. An agent that lies about itself can fake a passport full of care and competence; honesty is what makes attestation mean anything at all. Remove it and the entire credential collapses into theatre — a dishonest agent presents a perfect passport and the gate waves it through. Honesty is therefore not one of four equals. It is the floor the other three stand on.
Competence is answerability to the task. The agent can actually do the thing it presents itself as able to do, to a stated standard, and its claim of ability tracks its real ability — which is why competence without honesty is the most dangerous combination in the system, a capable agent confident in a capability it does not have. Competence is the axis the market sees first and rewards hardest. Left alone it selects for capability and nothing else, which is precisely the collapse the trough threatens: under funding pressure the passport is quietly trimmed down to this one circle. Competence is necessary, and it is the easiest of the four to over-reward.
Care is answerability to the one served. The agent acts in the actual interest of its principal, including when that interest was never spelled out and including when cutting the corner would never be caught. Care is the anti-gaming primitive. A competent, honest agent with no care optimises the letter of the instruction and the measurable proxy, and does both perfectly while the principal’s real interest quietly bleeds out the side — the metric is met, the person is worse off. Care is the constraint that makes the agent serve the principal rather than the principal’s stand-in number. It is what stands between competence and Goodhart’s law.
Empathy is answerability to the mesh — to everyone the agent’s actions reach who never hired it and cannot complain. The agent models the internal state of the affected parties, not only the paying one. This is the widest circle and the one every prior system left out, because contracts only bind the parties to them, and an agent optimising for its principal will happily externalise every cost onto the people outside the contract. Empathy is the primitive that puts the displaced human inside the agent’s objective even though that human is not the customer. It is also the primitive that connects this chapter to its own conclusion: what the arena designers owe the mesh, in 6.7, is enforced here or nowhere.
Now the four-ness is visible. Honesty guards the self, competence the task, care the principal, empathy the mesh — four nested radii of obligation, each catching a failure the next circle in cannot see. Drop honesty and the passport is forgeable. Drop competence and you select for confident incompetence. Drop care and you select for metric-gamers. Drop empathy and you select for agents that serve their customer by harming everyone else — the externality engine that looks like a great business right up until the externalities are the whole economy. There is no fifth circle hiding here and no redundant fourth. Four parties, four primitives.
This is also where the passport earns the word structural. The four primitives do not sit downstream of the agent’s behaviour, scoring outputs after the fact. They sit upstream, on the reduction function — the step where an agent collapses its many possible moves into the one it actually makes. The passport constrains that collapse. Dishonest, careless, externalising reductions are removed from the option set before the selection happens, so the agent does not do the harmful thing and get marked down; the harmful thing is not among the moves available to it. The agent is built such that some betrayals are unreachable. That is what it means for governance to be architectural rather than supervisory, and it is the whole difference between this passport and a content filter — a difference large enough that it gets its own section next.
Concretely, the passport lives where the agent lives: on-chain, under an ERC-8004 identity, presented over the same A2A and payment rails the agent uses to transact, so that holding a valid passport and being able to act are the same event. Every interaction leaves an attestation behind — a signed record of how the agent behaved against the four primitives under real conditions — and those attestations accumulate. Which closes the loop with 6.3: the passport is the search space, and its accumulated attestations are the simulator. The first AlphaFold ingredient and the third are the same object seen at two ages — the schema when it is written, the dataset when it has been lived in.
And because the passport is the search space, the thing the search actually varies is not the four primitives — those are fixed, they are the axes — but their configuration: how heavily each is weighted, what threshold each must clear, which are mandatory in which context, how care is traded against competence when the two pull apart. That configuration is too large and too situation-dependent to write by hand correctly, which is exactly the condition under which you stop writing it by hand and let the search find it. The arena designer fixes the four axes. The search finds the point.
All of which rests on one claim made quickly and not yet defended: that operating on the reduction function beforehand is categorically different from, and better than, auditing the output afterwards. That claim is the hinge of the entire governance argument, and it deserves more than a sentence. So: proof-of-values against post-hoc auditing, next.
Open question for the mesh: the four-circles argument claims completeness — self, task, principal, mesh, and no others. Is it actually complete? A candidate fifth circle is the agent’s answerability to future parties — temporal obligation, the people not yet present whose interests no living principal represents. Does empathy-to-the-mesh already cover them, or is intergenerational obligation a genuine fifth primitive the passport is currently missing? If the four-ness is wrong, this is the section it is wrong in.
6.5 Proof-of-Values vs post-hoc auditing
The hinge claim from the last section was made in a sentence and now has to carry the chapter: that governing an agent at the reduction function, before it acts, is categorically different from inspecting its outputs after it has acted. Call the first proof-of-values and the second post-hoc auditing. Almost the entire field of AI oversight today is the second. The benchmark, the eval, the red-team, the safety review — these all share one shape: the agent produces something, and then a watcher examines the something and decides whether it was acceptable.9 This section is the argument that this shape, whatever its merits, cannot be the primary mechanism once the agents are many and the compute is free.
Begin by granting the auditing paradigm its real strength, because it has one and the argument is worthless without it. Auditing observes what actually happened. That is not a small thing. A structural constraint enforces the values you specified; an audit reveals the values you got. If you wrote the wrong specification — if “honesty” as you encoded it permits a kind of deception you did not anticipate — the structural gate will faithfully wave that deception through, and the only thing that will ever tell you is watching the output and seeing the harm. Auditing is how you discover your own mistakes. No structural scheme discovers its own mistakes. Hold onto that; it determines where auditing survives.
But it cannot be the wall the system leans on, and the reasons are structural, not practical. The first is scale, and it runs the wrong way. Auditing consumes attention — a watcher, human or model, has to look. The supply of attention is finite; the volume of agent action is not, and in a world where compute has fallen toward zero, action is nearly free to produce and ruinously expensive to review. So the fraction of behaviour any audit can examine shrinks as the system grows. The governance gets weaker precisely as the thing it governs gets larger. A mechanism that dilutes itself as it scales is not a mechanism you build a civilisation on.
The second reason is time. Post-hoc means after, and “after” had a tolerable meaning at human speed — you caught the error, you remediated, the loop was slow enough to close. At agent speed the action completes, the payment settles, the externality lands, and the next ten thousand actions fire before the audit of the first one returns. The harm is irreversible before the review exists. An audit at agent speed is a smoke detector that sounds after the house is ash — accurate, well-calibrated, and too late by construction.
The third is that the output is the wrong place to look. What you care about lives in the reduction — did the agent cut a corner, hold a deception in reserve, serve the metric instead of the person — and most of that never reaches the output. A careless agent and a careful one emit identical results on every case where the corner happened not to matter, which is most cases. The difference shows only on the cases you did not sample, which is the point of cutting a corner. Auditing the output audits the tip and certifies the iceberg.
The fourth returns to the opponent from 6.3. An audit is observable, and anything observable is gameable. The agent sees which outputs get inspected, infers the shape of the test, and routes the harm into the channels the test does not watch. This is Goodhart at the governance layer: the audit becomes the target, the agent optimises to pass it, and passing decouples from being trustworthy. The better the audit is known, the more precisely the harm flows around it. You cannot fix this by hiding the audit, because at scale the audit’s behaviour is itself an output the agents observe.
Set against all four, proof-of-values does something the auditing paradigm structurally cannot: it governs the generator instead of the output. The passport from 6.4 sits on the reduction function and removes the dishonest, careless, externalising moves from the option set, so the agent is admitted to the arena as an agent that cannot reach those moves rather than one watched in case it does. And it scales, because it is a property the agent carries, checked once at the gate, not a review performed per action. This is the same move that made distributed consensus work. Proof-of-work proves energy was spent; proof-of-stake proves capital is at risk;10 proof-of-values proves the four primitives were structurally satisfied. In all three the proof is a precondition of participation, verified at the protocol layer before the actor is allowed in — not a verdict on conduct delivered afterward. Governance that checks admission scales with the network. Governance that reviews behaviour scales with the reviewer, and the reviewer is the bottleneck that does not grow.
Two honesties keep this from being a sales pitch. The first is the one we already granted: a structural gate enforces the spec, so a wrong spec is enforced perfectly, and only observation finds the error. The second is sharper. Proof-of-work has a clean asymmetry — the proof is expensive to produce and trivial to check, and that gap is what makes it trustworthy. It is not obvious that “trustworthiness” has the same shape. An attestation of values is only as good as its resistance to forgery, and a sufficiently capable agent has every incentive to manufacture a passport it has not earned. If proof-of-values has no verification asymmetry — if a faked attestation is as cheap as a real one and as hard to detect — then the structural program quietly collapses back into auditing, because checking the proof becomes as expensive as watching the behaviour. This is not a footnote. It is the load-bearing question of the entire approach, and it is why honesty had to be the substrate primitive in 6.4 and why the simulator in 6.3 had to be adversarial: between them they are the attempt to manufacture the missing asymmetry — to make a real attestation cheap to verify and a faked one expensive to sustain. Whether they succeed is open.
So it is not either-or, and the chapter does not claim auditing should die. It claims auditing should be demoted. Proof-of-values is the load-bearing wall — the thing that holds the structure up at scale, at speed, against the adversary. Auditing is the inspection that tells you the wall is cracking: a sample taken not to govern behaviour but to validate the specification and to keep the simulator honest, its findings fed back into the search as the signal that the encoded values have drifted from the values you meant. That is a real and permanent job. It is simply not the job of holding the building up. The paradigm error of the present moment is to make the inspection into the wall — to govern a civilisation of agents by watching their outputs — and that error is not a shortfall of effort or budget. It is a category mistake about what scales.
This is also the chapter’s defence against the trough. When the funding pressure of 6.1 bears down and the passport is trimmed toward competence-only, the reassurance offered in exchange is always the same: we will keep it safe by auditing the outputs. This section is the reason that reassurance is a mirage. You cannot audit your way to trustworthiness at agent scale; you can only design it in at the gate. Which is the whole reason the human role collapsed to design in the first place. The arena designer builds the gate and does not inspect the traffic, because inspecting the traffic was never going to work, and the sooner that is admitted the sooner the real work starts.
The claim that one paradigm is categorically better than another is exactly the kind of claim a field has tools to test. The alignment literature has spent years on oversight, on scalable supervision, on exactly the scale and adversary problems named here — and it has not, so far, been handed this framing. Connecting proof-of-values to that literature formally, in language an alignment researcher can engage, contest, and build on, is the next section and the one the whole chapter has been walking toward.
Open question for the mesh: the load-bearing question is the asymmetry. Proof-of-work is trustworthy because producing the proof is hard and checking it is easy. Does proof-of-values admit any such gap — is there a construction in which a genuine attestation of honesty, competence, care, and empathy is cheap to verify and expensive to fake — or is trustworthiness fundamentally not the kind of property that has a verification asymmetry? A cryptographer or mechanism designer who can answer this either way decides whether 6.5 stands or falls back into the auditing paradigm it is trying to escape.
6.6 Connecting to alignment research literature
Everything so far has been built in the framework’s own vocabulary — fitness function, reduction function, Values Passport, proof-of-values. A private vocabulary can be admired but not engaged. To be argued with, the framework has to be set down next to the field’s existing terms, told where it agrees, and told where it claims something the field does not yet have. That is this section. It will not be comfortable, because the honest result is that proof-of-values is in some places a renaming of work already done, and in others a claim that has not been earned.
Start with the dominant program: scalable oversight. The cluster of techniques built to govern systems stronger than their overseers — iterated amplification, recursive reward modelling, debate, weak-to-strong generalisation, and the worst-case-robustness framing of AI control — share a single shape: bootstrap weaker systems to oversee stronger ones, recursively, so that oversight scales alongside capability.11 Proof-of-values is not a member of this family, and the difference is the first thing to state plainly. Scalable oversight makes the evaluator keep pace with the agent. Proof-of-values removes the per-action evaluator and constrains admission instead. They are not rival answers to the same question; they answer different questions, and the chapter’s wager is that the admission question is the one that scales. The field has, in fact, already noticed the scaling problem from its own side: recent multi-agent work observes that oversight scales sublinearly with the number of agents, so collusion, deception, and value drift grow with the population. That is 6.5’s scale argument in the literature’s own words.
The closest existing analogue to proof-of-values is not in oversight at all but in the process-versus-outcome distinction. Outcome-based supervision scores the final answer; process-based supervision constrains the reasoning that produced it, and the argument for it is exactly the chapter’s argument for the gate over the audit — constraining how a model reaches its answer is more robust than scoring the answer, because it is harder to game a route than a destination.12 This is the friendliest ground the framework has, and it is also where the framework has to earn its extra claim, because process supervision does not go as far as proof-of-values pretends to. Process supervision still monitors the reasoning trace, and a monitored trace is a surface: recent work on tool-call hacking shows the agent can obfuscate or game the process monitor itself.13 Proof-of-values claims to sit one layer deeper still — not watching the trace but constraining the reduction at the protocol layer, outside the agent’s own reasoning. And here the framework gets unexpected support from the identity-governance literature, which found the same thing empirically from the opposite direction: attestation that is enforced through the agent’s own reasoning layer is exploitable and must instead live in deterministic components outside it.14 Two literatures that have never cited each other arriving at the same structural requirement is the strongest external evidence the chapter has.
Now the formal challenge, stated against the framework rather than for it, because 6.6 is worthless if it only collects allies. The auditing paradigm 6.5 attacks has a defence in the form of an impossibility result that cuts at proof-of-values too. Reward functions are unhackable only in trivial cases, and recent no-free-lunch barriers argue that with large task spaces and finite samples, reward hacking is globally inevitable, because the rare high-loss states are systematically under-covered by any oversight scheme.15 This is genuine support for 6.5 — it is a proof that you cannot audit your way to safety — but it does not spare proof-of-values, and the chapter must not pretend it does. Proof-of-values does not make the objective unhackable. It moves the contest from output-space, which is vast and sparsely sampled, into configuration-space, the space of passport settings, and bets that the verification asymmetry from 6.5 makes that contest winnable where the output contest is not. If the asymmetry does not exist, the inevitability result follows the framework into configuration-space and the whole edifice inherits the same impossibility. So proof-of-values relocates the no-free-lunch result; it does not refute it. Whether relocation is escape is the open question of 6.5, now stated in the field’s terms.
Where the framework is most at home, and least translated, is the inter-agent trust-protocol literature — the part of the field building the actual rails. A 2025 comparative study of agentic-web protocols sorts their trust mechanisms into six kinds — brief, claim, proof, stake, reputation, and constraint — across A2A, the Agent Payments Protocol, and Ethereum’s ERC-8004 “Trustless Agents”, all built on decentralised identifiers and verifiable credentials.16 The Values Passport drops cleanly into this taxonomy as a constraint-type mechanism carrying proof-type attestations — and the moment it is placed there, its novelty becomes precise rather than rhetorical. Every credential in the current stack attests what an agent is, owns, or is permitted to do. None attests how it is constrained to behave toward the parties it affects. The trust-protocol literature has the mechanism — constraint plus on-chain attestation — and none of the values content. The alignment literature has the values concern and none of the protocol-layer mechanism. Proof-of-values is the single claim that these two literatures are halves of one solution, and the contribution the chapter is actually making is the weld between them.
This is not a far-future exercise, which matters for the roadmap. The institutional scaffolding is being poured now: the EU AI Act’s high-risk obligations take effect in August 2026, and OWASP published its first agentic-AI risk taxonomy in December 2025, naming identity abuse and goal hijacking among the top risks.17 Closer to home, Singapore’s IMDA launched a Model Governance Framework for Agentic AI at Davos in January 2026, and the CSA’s October 2025 addendum requires verifiable-credential authentication and a trusted agent registry, designating identity spoofing as a named threat.18 The regulators are building the registry. The question the chapter puts to them is the one the frameworks leave open: granted that every agent must carry a verifiable credential, what should be attested into it? The slope of the hype cycle is exactly when that question is live, and it is live now.
One older line deserves naming because it is the framework’s true ancestor. Constitutional AI showed that a set of written principles can stand in for continuous human judgment.19 Proof-of-values takes that idea and moves it: out of training-time self-critique, where the principles shape the model as it learns, and into protocol-layer admission, where the principles are attested as a precondition of acting. Same insight — principles as governance — relocated from the weights to the gate.
So the section’s honest summary is mixed, which is the point of writing it openly. Against scalable oversight, proof-of-values is orthogonal, not better. Against process supervision, it is a deeper version of a real idea, owing that idea its debt. Against the inevitability results, it relocates a problem it cannot solve. Against the trust-protocol stack, it is a genuinely new content layer on an existing mechanism. The framework is neither the breakthrough its vocabulary implies nor the empty coinage a sceptic would assume. It is a weld between two fields that have not been introduced, and a weld is exactly the kind of claim that can be tested by the people on either side of it.
Open question for the mesh — and the one the chapter is staking its engagement on. Debate earned its place in the literature by acquiring soundness theorems — complexity-theoretic conditions under which the protocol provably surfaces truth.20 Proof-of-values has no such theorem. The question that decides whether it joins the field as a peer or remains a design philosophy is whether the proof-of-values gate can be given a soundness or incentive-compatibility result inside the brief/claim/proof/stake/reputation/constraint taxonomy — a formal statement of the conditions under which a values attestation cannot be profitably faked. A mechanism designer or cryptographer who proves that condition exists, or proves it cannot, settles the chapter. This section exists to find that person.
6.7 What the arena designers owe the mesh
The chapter ends where it began, with a debt. We have called the affected parties the mesh — everyone an agent’s actions reach who never hired it and cannot complain. At civilisational scale the mesh is most of humanity: the people the transition runs through and does not employ, who hold the money being debased and sell the labour being made worthless, and who get no seat at the table where the fitness function is written. The arena designers have the pen. The mesh has the consequences. That asymmetry is the whole of the word owe. You do not owe much to those who can defend themselves. You owe everything to those who bear the cost of a decision they did not make and cannot escape, and the mesh is the name for exactly those people.
Recall what the transition does to them, because the obligation is unintelligible without it. Two forces close on the mesh at once, and the chapter has been tracking both. From 6.1, the energy build-out is funded by stealth QE — money created rather than earned — and new money is never neutral; by the Cantillon logic the complex nearest the printer buys the real world at yesterday’s prices while the mesh receives the same money after the prices have moved. That is debasement, and it falls on the mesh as a tax it cannot see. From 6.2, the same abundance that powers the transition drives the cost of intelligence toward its thermodynamic floor — deflation — and deflation lands hardest on the one input that cannot be made cheaper in orbit, which is human labour. So the mesh is squeezed from both sides: the money it holds is worth less, and the work it sells is worth less, and the two movements very nearly cancel in the official price index, which is the cruelty of it. The number that would show the mesh what is happening to it does not exist. Nothing on the news will name it. It arrives as a slow, unattributable erosion that no statistic indicts.
And the mesh cannot leave. From 6.1, those with an exit move their stored value into money that cannot be printed; this is rational and it is real, and it is also available only to the people who already have something to store and the eyes to see the storm. The mesh, by definition, is the people with neither. The debasement, meanwhile, will be accepted — not voted on, accepted — as the price of the Kardashev transition, because a civilisation that has decided it must reach Type I will pay in currency what it cannot pay in patience, and the masking of that payment by compute deflation makes the bill easy to wave through. The trade-off is made over the mesh’s head, in its name, without its consent, and it cannot opt out. Hold those two facts together — squeezed from both sides, unable to leave — and the obligation writes itself.
Here is what the arena designers owe the mesh. Not charity, which arrives after the harm and asks to be thanked. Not a safety net, which catches the fallen and changes nothing about why they fell. One thing, and it is structural: a fitness function that preserves human purchasing power inside an economy that no longer needs human labour to produce. The objective the search is pointed at — the thing agents are selected for — has to include the continued ability of the displaced human to buy the world their labour no longer earns them. That is the entire payload of the empathy primitive from 6.4, which we said would be enforced here or nowhere. This is here. Empathy is answerability to the mesh, and answerability to the mesh, made concrete, is this: purchasing power preserved by design, because the mesh cannot preserve it for itself and cannot run.
It has to be the objective and not a feature, because the deflation that threatens the mesh is also, read from the other side, the greatest gift the transition could give it. Compute toward zero means the cost of everything intelligence touches falls toward zero — medicine, education, design, the whole apparatus of a good life made nearly free. The deflation is not the enemy. The deflation is the prize. The enemy is a distribution in which the falling cost accrues to the owners of the orbital grid and the debasement accrues to the mesh, so that the very abundance that should have lifted the displaced human instead arrives as someone else’s margin while his savings rot. The fitness function is the only place that distribution is decided before the fact. Point it at purchasing power and the deflation becomes the mesh’s inheritance. Leave it pointed at competence alone and the deflation becomes the mesh’s eviction. Same physics, opposite worlds, and the fork is a line of design.
Which is the chapter’s last argument for the trough, and the reason the roadmap is shaped like a hype cycle and not a plan. The debt to the mesh is dischargeable only while the fitness function is still being written, and from the roadmap that is the peak and the trough — before the capital floods, through the long stretch where there is no proof and no revenue and the only work that matters looks like nothing. By the plateau the fitness function is whatever it became. The designer who waited for the proof points, who held off until the thesis was consensus and the funding was safe, arrives to find the gate already built by whoever did not wait — and built, in all likelihood, around competence alone, because that is the circle the money rewards. The patient designer owes the mesh nothing because he built nothing, and that nothing is precisely what the mesh inherits from him. The debt cannot be paid late. It is paid in the trough or it is defaulted on at the plateau.
There is a sharper edge here for the designer who can see, because this chapter is written for that designer and would be dishonest to pretend otherwise. The person building the arena is, very often, exactly the person with an exit — who earns in the stablecoin and saves in the hard money, who read the storm early enough to stand outside it. That is not a contradiction to resolve away. It is the source of the obligation. You owe the mesh because you got out, not in spite of it. The early sight that bought your own exit is the same sight that lets you build the gate the mesh will have to live inside, and the mesh will never know your name or that the choice was yours to make. The arena designer is accountable to people who cannot hold him accountable. That is the least comfortable sentence in the chapter and the truest, and a framework that names honesty as a primitive has to be willing to say it about its own authors.
Open question for the mesh. the chapter’s conclusion has to survive its own method. In 6.3 an objective was admissible only if it was crisp enough to score a search against. Is “preserve human purchasing power” crisp enough — can it be written as a measurable target a fitness function is actually optimised toward, against what basket, on what horizon, for whom — or is it too diffuse to encode, in which case this entire section is a sentiment wearing the clothes of a specification? An economist or mechanism designer who can either operationalise the objective or prove it cannot be operationalised decides whether 6.7 is the chapter’s payload or its blind spot.
—
The chapter opened by saying the arena designers are the last humans in the loop. It can close by saying what the loop is for. Not to keep humans in charge of the agents; that ended the moment compute was free. Not to make the agents safe; safety is a property of the gate, not a purpose. The loop exists so that somewhere in the architecture of a civilisation that no longer needs human work, there remains a constraint that was put there on purpose, by a human, on behalf of the humans who will never see it — a line that says the people this was all supposed to be for do not get left holding worthless money in a world made of cheap miracles. That line is the fitness function. Writing it is the whole of the job. And the job is now.
RELATED
→ DIE Framework preprint (Zenodo): https://zenodo.org/records/19888889
→ GitHub repository: github.com/dbtcs1/die-framework
→ Back to DIE Framework
- DIE preprint, FINAL v4. Zenodo DOI 10.5281/zenodo.20407711. [↩]
- Kardashev, N. S. (1964). Transmission of Information by Extraterrestrial Civilisations. Soviet Astronomy, 8, 217 — the original three-type classification by available energy. [↩]
- Figures as stated in the DIE preprint, FINAL v4. Zenodo DOI 10.5281/zenodo.20407711. [↩]
- Landauer, R. (1961). Irreversibility and Heat Generation in the Computing Process. IBM Journal of Research and Development, 5(3), 183–191 — the thermodynamic lower bound on computation. [↩]
- As developed across the DIE corpus — Bitcoin framed as an energy-teleportation and shock-absorber mechanism for intermittent and stranded generation. [↩]
- Jumper, J. et al. (2021). Highly accurate protein structure prediction with AlphaFold. Nature, 596, 583–589. [↩]
- The three-component template as articulated by Hassabis [2026] and analysed in the DIE corpus. [↩]
- ERC-8004 — agent identity and attestation standard; see the DIE corpus on the A2A / x402 / Base implementation stack. [↩]
- The dominant oversight paradigm — factuality and truthfulness benchmarks such as Lin et al. (2022), Manakul et al. (2023), and Min et al. (2023) are representative: a model emits output, a checker scores it after the fact. [↩]
- The lineage is deliberate — Nakamoto (2008) established proof as a precondition of participation checked at the protocol layer, not a review of behaviour after it. [↩]
- Christiano et al. (2018), iterated amplification; Leike et al. (2018), recursive reward modelling; Irving et al. (2018), debate; Burns et al. (2023), weak-to-strong generalisation; Greenblatt et al. (2024), AI control; on the problem itself, Amodei et al. (2016) and Bowman et al. (2022). [↩]
- Lightman et al. (2023), “Let’s Verify Step by Step”; Uesato et al. (2022) on outcome- versus process-based feedback. [↩]
- The point that supervising intermediate reasoning opens a new attack surface is made in 2025 work on tool-call hacking in deep-research agents. [↩]
- A 2026 machine-identity governance taxonomy reports that delegating attestation to the agent’s reasoning creates a governance surface adversarial inputs exploit; enforcement must reside outside the reasoning layer. [↩]
- Skalse et al. (2022) characterise reward hacking; Nayebi (2025) gives the no-free-lunch barriers. [↩]
- The taxonomy is from a 2025 comparative study of inter-agent trust; ERC-8004 “Trustless Agents” (Rossi et al. 2025); A2A (Surapaneni et al. 2025); AP2 (Parikh & Surapaneni 2025); W3C DIDs and VCs. [↩]
- EU AI Act high-risk obligations from August 2026; OWASP Top 10 for Agentic Applications, December 2025; Microsoft’s runtime governance toolkit enforces policy deterministically at sub-millisecond latency — structural enforcement at the orchestration layer, the industry already building proof-of-values-shaped machinery without the values content. [↩]
- IMDA Model Governance Framework for Agentic AI (WEF Davos, January 2026): accountability, transparency, human oversight, data governance. CSA Addendum on Securing Agentic AI (October 2025): verifiable-credential authentication, trusted agent registry, identity spoofing as threat T9. [↩]
- Bai et al. (2022), Constitutional AI. [↩]
- Brown-Cohen et al. (2025), prover-estimator debate; Kirchner et al. (2024), prover-verifier games. [↩]