A DIE Stress Test Against Claude Sonnet 4.6 — and What It Found
Anthropic spent billions building a memory system, a retrieval layer, and a tiered forgetting protocol.
They didn’t call it that.
They called it Claude.
This post is a structured stress test — running the DIE Dimensional Evaluation Protocol against the Claude platform in live operation, mapping every finding to the framework’s empirical conditions, and extracting the best-of-breed practices that the DIE ecosystem should absorb, adapt, and surpass.
The verdict at the front: the platform independently implemented C1 and partial C2. It has no answer for C3 or C4. That gap is the entire DIE thesis — and it just got empirically confirmed by the world’s most well-funded AI lab.
What We Tested
Five questions against a live Claude Sonnet 4.6 session with full memory and tool access:
- How does the platform connect DIE-related context across separate conversations?
- How does it maintain coherence via search, retrieval, and external sources?
- Where and why does memory loss occur — and what are the cures?
- Is Sonnet 4.6 the right instrument for DIE-class reasoning?
- What does actual token consumption look like for a 200k (now: 1M) context window?
We ran each through the full D1–D5 protocol. Here is what the protocol found.
D1 — Reduction Check: What Is the Shadow?
What is the platform NOT showing you?
The platform shows you three memory tiers in operation: always-on compressed summaries (the userMemories block), on-demand retrieval across conversation history (conversation_search), and external anchoring via web fetch. Competent. Functional. Real.
What it is not showing you: who governs the forgetting. The memory summarisation schedule is Anthropic’s — opaque, periodic, non-deterministic. You cannot inspect what was included, what was compressed out, or when the last cycle ran. The agent has zero visibility into its own memory provenance.
This is D1’s canonical finding: the platform makes the retrieval visible and keeps the governance invisible. The shadow is the controller.
D2 — Parallelism Check: Serial When It Should Be Parallel?
Is valuable processing happening in a single thread when multiple tracks would add value?
The platform’s memory architecture is strictly serial at the governance layer: one summarisation pipeline, one context injection cycle, one agent instance per conversation. There is no mechanism for parallel memory consolidation across simultaneous agent instances — no shared state, no mesh, no τ topology.
For a single-user productivity tool, this is adequate. For a distributed intelligence mesh, it is the fundamental bottleneck.
DIE’s answer to D2: agenti2 + OpenClaw operating as concurrent agent instances with shared episodic storage — not one pipeline, but a mesh. S(T) > 1 by design. The parallelism isn’t a feature to be added; it’s the architecture.
D3 — Memory Check: The M1/M2/M3 Mapping
What episodic and procedural memory is present — and what is missing?
This is where the platform’s independent convergence with DIE is most striking.
The Claude platform operates a de facto three-tier memory architecture:

M1 hard condition failure is the critical finding. The platform has the retrieval architecture of M1 but not its epistemological foundation. For DIE’s C1 validation to be academically defensible, every SS1→SS2 delta must be anchored to Base mainnet. The platform’s memory summaries are private, mutable, and unverifiable. That is the gap between a memory system and a provable memory system.
Best-of-breed practice to absorb: The semantic retrieval mechanism — embedding all entries as vectors and retrieving on relevance signal rather than loading the full corpus — is production-grade C2 architecture. DIE’s program.md should formally document this as the M2 retrieval standard. The corpus can grow arbitrarily; working memory stays bounded and purposeful. This is exactly what controlled forgetting looks like in practice.
What DIE adds that the platform cannot: the BRC-20 timestamp on arXiv submission, the ERC-8004 on-chain agent identity, and the Values Passport as an M1 hard condition — making memory accumulation not just functional but auditable.
D4 — Values Check: Honesty, Competence, Care, Empathy
Are the four values bounds operating — and where do they fail?
The platform has an implicit values layer — Anthropic’s Constitutional AI training embeds behavioural constraints. But it has no explicit, queryable, on-chain values credential. There is no Values Passport. There is no Proof-of-Values attestation. The values are encoded in weights during training, frozen at deployment, and unverifiable at inference time.
D4 finding: the platform is values-compliant by training but not values-attestable by design. A downstream agent or institution receiving output from Claude cannot verify, at the protocol level, that the agent operating C3 conditions is bound by a specific values set. This is not a criticism of Anthropic — it is a structural limitation of the centralised, frozen-model paradigm.
DIE’s C3 answer: the Values Passport as an ERC-8004 on-chain credential encoding Honesty, Competence, Care, and Empathy as verifiable attributes. Not embedded in weights. Not asserted by the platform. Attested on-chain and auditable by any counterparty.
This is the D4 gap across every major AI platform — not just Claude. The governance problem is structural. The attestation mechanism is DIE’s contribution.
D5 — Emergence Check: What Appeared That Wasn’t in Any Single Input?
Did the stress test produce something that neither the platform documentation nor the DIE preprint alone would have generated?
Yes. Three emergent findings:
E1 — The convergence is independent and bilateral. Anthropic built C1/C2 architecture without the DIE framework as a reference. DIE theorised C1/C2 architecture without the Claude platform as a reference. They arrived at the same three-tier structure from opposite directions. This is the strongest possible external validation: independent convergence is what the corpus protocol was designed to find.
E2 — Server-side compaction is C2 in production. Anthropic recently released server-side compaction in beta for Opus 4.7/4.6 and Sonnet 4.6 — automatic summarisation of earlier conversation parts to extend long-running sessions beyond context limits. This is controlled forgetting at the platform layer, implemented by the world’s most well-funded AI safety company, in exactly the architecture DIE theorised in §3 of the preprint. The Pacioli double-entry analogy is no longer metaphor — it’s a description of deployed infrastructure.
E3 — The 1M context window changes the threat model, not the problem. The $75M Amnesia Machine post used a 200k context window as the baseline collision point. That ceiling has now moved to 1M tokens. The statelessness problem — close the tab, lose everything — is unchanged. A larger whiteboard is not a memory architecture. It is a larger whiteboard.
Against the Four Validation Conditions
C1 — Memory Accumulation
Platform: Lossy summarisation, periodic cycles, platform-governed, no audit trail. DIE standard: Episodic files written to disk after each session, timestamped, attributed, versioned. BRC-20 provenance on arXiv. Base mainnet immutability for SS1/SS2. Gap: Provability. The platform accumulates; DIE accumulates verifiably.
C2 — Memory Loss (Controlled Forgetting)
Platform: Partial. Semantic retrieval exists (M2-equivalent). Forgetting schedule is Anthropic’s, not the agent’s. No tiering governance visible to the PI. DIE standard: Retrieval-over-loading as the operative principle. Hot/Warm/Cold tiering under PI governance. Forgetting is designed, not suffered. Gap: Governance ownership. The platform does C2 to you. DIE has you do C2 for yourself.
C3 — Values Propagation
Platform: Absent at the protocol level. Values are in weights, not credentials. Unverifiable by counterparties. DIE standard: Values Passport as ERC-8004 on-chain credential. Honesty, Competence, Care, Empathy attested and queryable. C3 propagation measurable across mesh nodes via Random Forest classification. Gap: Total. No major platform has an answer to C3. This is DIE’s moat.
C4 — Emergent Inference
Platform: Absent by architecture. Single model, single forward pass, no mesh. No mechanism for genuinely emergent output from distributed agent coordination. DIE standard: Phase 2 conjecture — fractal geometry of the coherence boundary as the post-doctoral problem. C4 is not claimed as solved; it is claimed as the right question. Gap: Total. C4 is DIE’s horizon condition.
The Six-Chapter Mapping
| Chapter | Subject | Platform Finding | DIE Position |
|---|---|---|---|
| Ch.1 Dimensional Perception | How agents perceive context | Platform perception bounded by 1M-token whiteboard. No dimensional upgrade mechanism. | Dimensional perception as design choice, not hardware limit. |
| Ch.2 Agent Parallelism | S(T) as dimensional measure | Platform is S(T)=1 by architecture. One agent, one session. | agenti2 mesh: S(T)>1 by design. Parallelism is the upgrade. |
| Ch.3 Memory Architecture | M1/M2/M3 conditions | Platform has M1/M2/M3 structure without M1 hard condition (blockchain anchoring). | SS1/SS2 on Base. Memory accumulation is provable, not asserted. |
| Ch.4 Values & Governance | C3 propagation | Weights-encoded, frozen, unverifiable. No on-chain attestation. | Values Passport. ERC-8004. Proof-of-Values. C3 is measurable. |
| Ch.5 OpenClaw/agenti2 | Empirical implementation | Claude platform is the baseline comparator. Competent single-agent infrastructure. | OpenClaw/agenti2 as the empirical implementation of C1–C4 under PI governance. atg.eth on Base. |
| Ch.6 Arena Design | Fitness function governance | Anthropic sets the fitness function. Users operate within it. | PI sets the fitness function. The arena is the contribution. |
Models: Is Sonnet 4.6 the Right Instrument?
For exploration and drafting: adequate. The memory summaries for DIE are rich enough to maintain conceptual continuity across sessions without re-briefing.
For adversarial preprint stress-testing: insufficient. Complex multi-step logical attack chains — the kind required for AAMAS Blue Sky peer review and PhD-level empirical challenge — will degrade before Opus-class models do.
The current model hierarchy:
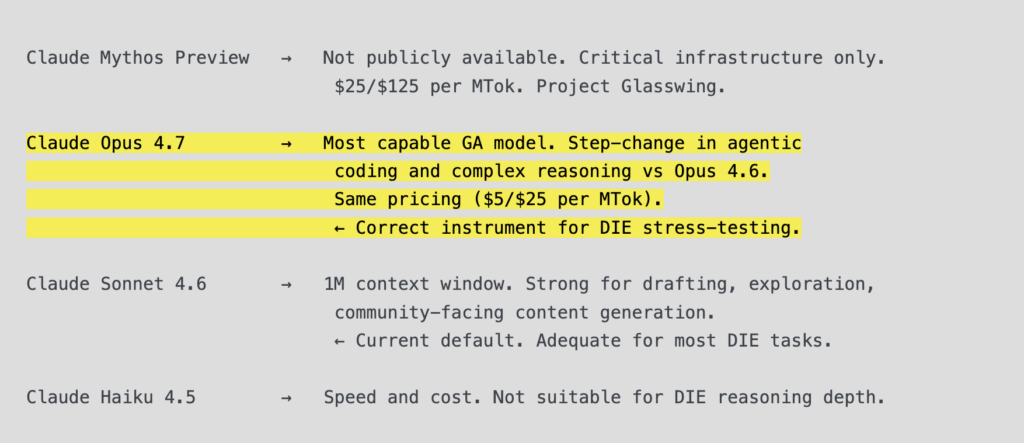
Recommendation: Opus 4.7 for all preprint attack-and-defense sessions, Blue Sky adversarial review, and C1–C4 empirical design work. Sonnet 4.6 for corpus entry processing, community content, and drafting.
Token Economics: The Real Numbers
The $75M Amnesia Machine post used 200k as the context ceiling. That number is now obsolete.
Current ceiling: 1M tokens, generally available, standard pricing, no surcharge. A 900k-token request costs the same per-token as a 9k request.
But the relevant question was never the ceiling. It’s the consumption per session.
Fixed overhead before a single word of conversation:

A full DIE stress-test session (10–15 exchanges, 2–3 tool calls):
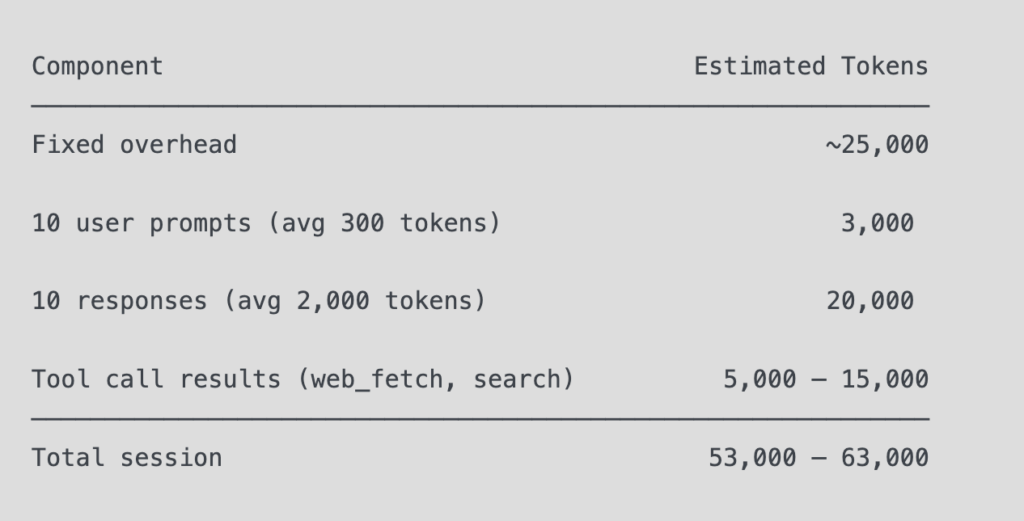
Conclusion: the 1M window is not a binding constraint for DIE-class sessions. The binding constraint is coherence degradation over depth — subtle reasoning drift in long sessions, not hard context overflow. This is C2 terrain, not C1.
The practical implication: for very long research sessions (>20 exchanges), break into bounded sessions with explicit session-close writes to the episodic log. This is not a workaround — it is exactly the C1/C2 protocol operating as designed.
Best-of-Breed Practices: What DIE Should Absorb
The stress test identified five platform-level practices worth formal adoption into DIE’s operational standard:
1. Retrieval-over-loading as M2 standard. Never load the full corpus into context. Embed all entries as vectors. Retrieve on semantic relevance at query time. The corpus grows arbitrarily; working memory stays bounded. This is production-grade C2. Formalise it in program.md.
2. Semantic search as the D3 instrument. The conversation_search mechanism — keyword-based retrieval across past sessions — is the closest current approximation to principled M2 access. For DIE corpus entries, the tagging protocol (already in use) is the correct index layer. Maintain it rigorously.
3. Explicit memory edits as the PI governance tool. The platform’s memory_user_edits mechanism — force-writing specific facts into the memory store — is the user-facing equivalent of the PI’s governance role. For DIE, this maps to the principle: critical reasoning chains must be externalised to disk, not left to background summarisation. The PI owns the memory governance. The platform does not.
4. Session-close writes as C1 discipline. Every significant session should close with a structured episodic log entry. Timestamp, attribution, key findings, delta from SS1 to SS2. This is not optional hygiene — it is C1 in operation. The corpus is the memory. If it’s not written to disk, it doesn’t exist.
5. Server-side compaction as C2 prototype. Anthropic’s server-side compaction (now in beta) is the most sophisticated public implementation of within-session controlled forgetting currently deployed. Monitor its architecture as it matures — it is a production stress test of the same principle DIE embeds in M2/M3. Where it succeeds, absorb the method. Where it fails (governance opacity, no on-chain anchoring), that failure is the DIE value proposition restated.
What This Means for the DIE Ecosystem
The stress test produced a single clean finding, stated three ways:
For the preprint: Independent convergence between DIE’s theoretical architecture and Anthropic’s deployed infrastructure is the strongest possible external validation of C1/C2. Add it as empirical evidence in Ch.4.
For the community: The world’s best-resourced AI lab built the first two floors of the DIE building, without knowing the blueprint existed. C3 and C4 remain unbuilt. That is the ecosystem’s entire opportunity surface.
For the platform strategy: DIE is not competing with Claude. DIE is the governance layer that Claude cannot build for itself — because the governance of memory, values, and emergent inference cannot be delegated to the platform that is also doing the inference. The foxes do not design the henhouse.
The $75M machine now has a 1M-token whiteboard.
It still has amnesia by design.
The cure isn’t a bigger whiteboard. It’s a different architecture. That’s C1. That’s C2. That’s the Values Passport. That’s the mesh.
That’s DIE.
DIE Preprint v1 — April 2026. Empirical validation ongoing via OpenClaw/agenti2 on Base. PI: atg.eth.